
Scraping local election results.
The recent local elections were a good chance for a quick reminder of how scraping can help quickly release the data trapped in the amber of HTML
The recent local elections were a good chance for a quick reminder of how scraping can help quickly release the data trapped in the amber of HTML
We’ve just had local elections here in England, so there’s a lot of data sloshing around — counts, turnout etc. When I looked at the results from my area, Manchester, I ran into a problem that most journalists and data people will recognise — A page full of results that’s easy-ish to read but not great if I want to do anything else with the numbers.
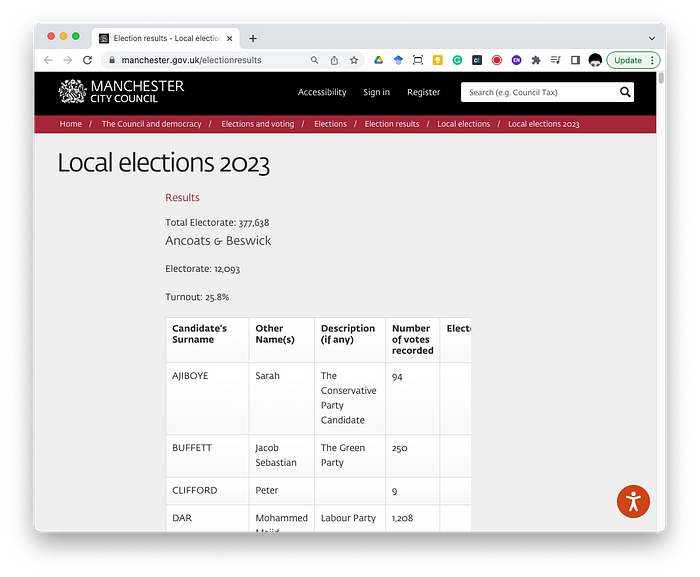
There are a couple of bits of valuable data here:
- The results from each ward
- The number and type of rejected ballot.
- The turnout/electorate for each Ward
The first two are nicely tabulated and the data can be quickly cut and paste into a spreadsheet. There is the odd bit of ‘dirty’ data here and there — the odd line break in candidate descriptions will throw Excel off. But it wasn’t too time-consuming to cut and paste each table into a spreadsheet.
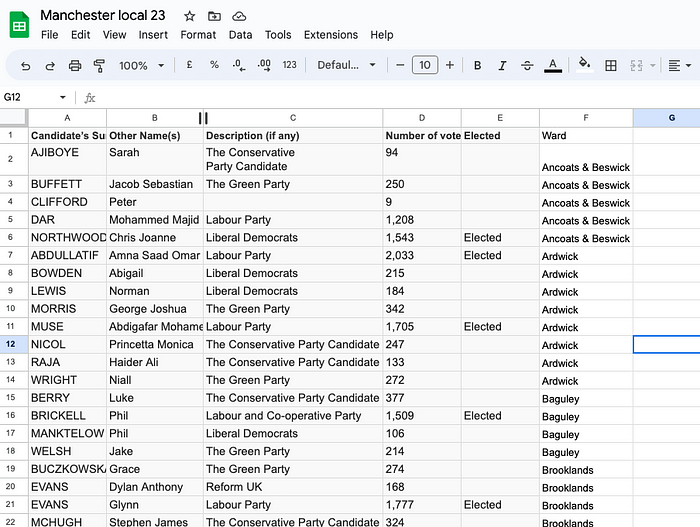
But the final bit — the turnout and electorate details - were not as nicely or obviously formatted. Each of them was added as a few lines before the results tables. Ideally, we would want the results from each ward as one table — ward, voters and turnout. Once in table form, we can do some analysis (highest/lowest) or visualisation.
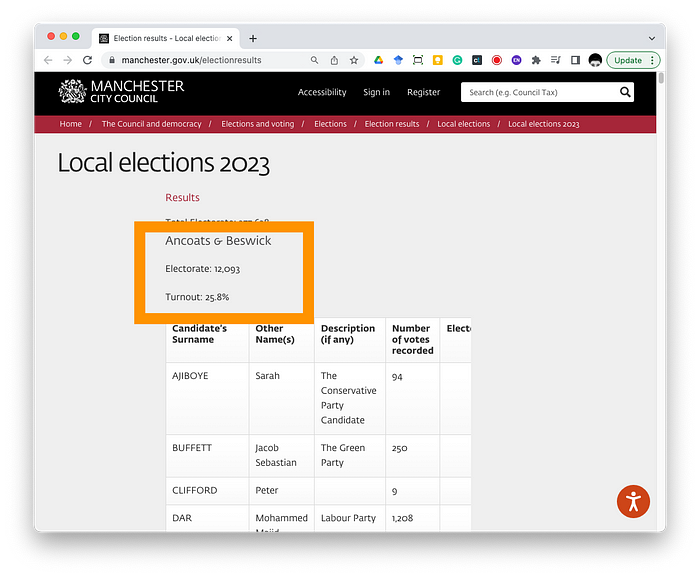
This is a textbook case for some web scraping. It’s something that would be a cut-and-paste marathon.
Find the thing to scrape
The key thing with web scraping is finding the way the content is described in the HTML, not the way it looks. You can then use that to direct your web scraping tool of choice. That means digging into the code.
The easiest way to do this is by using the Developer mode on your web browser. It allows you to inspect an element on the page and see what HTML tags have been used to describe the content.
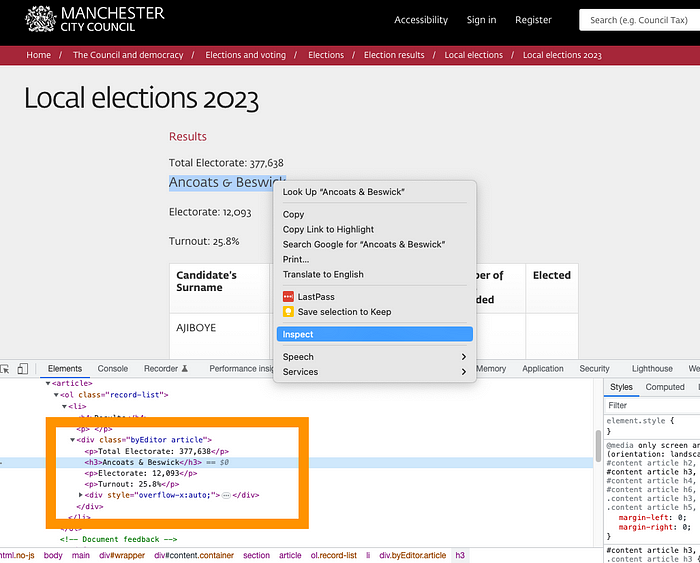
In this case, each Ward name was set as a heading (h3) and then the Electorate and Turnout figures in two paragraphs (p) below. A look across the rest of the page showed that this was the same for each ward.
Using this information I can describe the structure of what I want to do — I want to
- find every
h3on the page and store that as the Ward name - find the first
ptag after theh3and store that as the Electorate - find the second
ptag after theh3and store that as the Turnout.
There are loads of different tools and approaches to webscraping. But for this exercise, I wanted to stick with my general approach of finding tools that are open/free and easily accessible across the widest range of machines.* So I had a look at two
- Google Sheets, Google’s free spreadsheet app
- Python using Google Collab Google’s online runtime environment for code.
Google sheets method
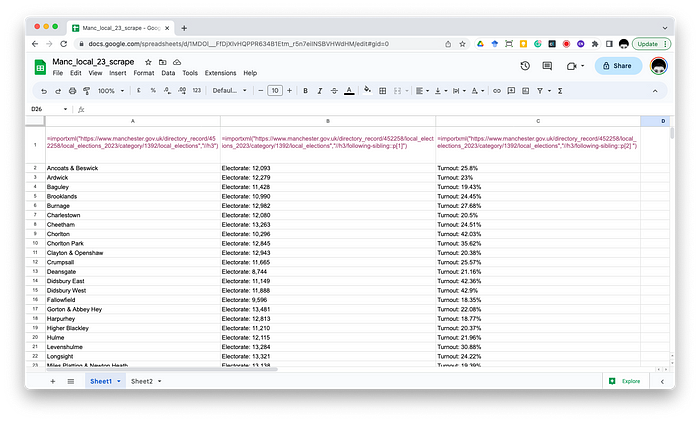
Google Sheets is a great tool for basic web scraping thanks to the formula =importXML() which “Imports data from any of various structured data types including XML, HTML, CSV, TSV and RSS and Atom XML feeds.” Here’s what Google sheets’ help says about the formula.
IMPORTXML(url, xpath_query)
url– The URL of the page to be examined, including protocol (e.g.http://).- The value for
urlmust either be enclosed in quotation marks or be a reference to a cell containing the appropriate text. xpath_query– The XPath query to be run on the structured data.
So we need to tell it where to look, what to look and what to look for. Here’s the formula I used:
=importxml(“https://www.manchester.gov.uk/directory_record/452258/local_elections_2023/category/1392/local_elections","//h3")
The URL is straightforward enough, it’s the results page. The tricky bit is the XPath query.
XPath
Xpath is essentially a set of directions based on the structure of the HTML. It allows you to describe what you are looking for as an HTML element or by its relationship to other elements. In principle, it's pretty intuitive. In practice, it can be a fiddle to get the right structure. There are some good sites with tutorials and overviews. I’m going to be controversial here (perhaps) and say that suggesting XPath statements based on a snippet of HTML is the kind of thing you might lean on chatGPT etc to do.
In this case, we are using //h3. The // means look everywhere/select all of something. So here it finds all the content of all the h3 tags. So when we add the formula it magically populates your spreadsheet with each h3 in a new row.
Now, it’s not perfect. I noticed that the last entry was “Was this page helpful?” Clearly, the feedback link at the end of the webpage was set as h3. But that’s an easy bit of cleaning/checking I can do later.
Things get a bit more complicated when it comes to grabbing the first p tag for our Electorate value:
=importxml(“https://www.manchester.gov.uk/directory_record/452258/local_elections_2023/category/1392/local_elections","//h3/following-sibling::p[1]")
The first bit is the same, the webpage address. But the XPath has expanded.
//h3/following-sibling::p[1]
Here we are asking XPath to find any h3 tags and then, when it does, look for the next tag, in this case, a p tag. The final part, [1] limits the results to the first p tag it finds. This is important because we know there's more than one p tag kicking around. Knowing that means it's not that hard to figure out how we might grab the second p tag for the turnout.
=importxml(“https://www.manchester.gov.uk/directory_record/452258/local_elections_2023/category/1392/local_elections","//h3/following-sibling::p[2]")
Notice how the only thing that’s changed is the [2]
- select the whole sheet and
Edit > Copy - start a new sheet
- select the first cell in your new sheet and select
Edit > Paste Special > Values only
You can then use find and replace to remove the Turnout: , Electorate:, and % from the results to give you clean numbers.
- Select the Electorate column and then
Edit > Find and replaceenterTurnout:in find and leave the replace blank (make sure to add a space after the : ) - Select the Turnout column and then E
dit > Find and replaceenterElectorate:in find and leave the replace blank (make sure to add a space after the : ) - Select the Turnout column and then
Edit > Find and replaceenter % in find and leave the replace blank
Finally, you can add a new row at the top for headers and delete that pesky “was this page helpful’ error and you have a clean sheet of stats to work with.
The Python/Colab approach
Once you get passed the XPath challenge, the importXML() formula becomes a pretty powerful tool for scraping. But it's not the only game in town. Lots of journalists (Data journalists) like to do this kind of thing in code.
The code below is some Python that will do the same thing as our Google formula and spit out a CSV file with the results.
import requests
from bs4 import BeautifulSoup
import csv
html = requests.get('https://www.manchester.gov.uk/directory_record/452258/local_elections_2023/category/1392/local_elections').text
soup = BeautifulSoup(html, 'html.parser')
h3_tags = soup.find_all('h3')
data = []
for h3 in h3_tags:
row = [h3.text]
next_siblings = list(h3.find_next_siblings('p', limit=2))
row.extend([sibling.text for sibling in next_siblings])
data.append(row)
del data[-1]
data = [[item.replace("Electorate: ", "").replace("Turnout: ", "").replace("%", "") for item in sublist] for sublist in data]
with open('mcr_vote.csv', 'w', newline='') as myFile:
writer = csv.writer(myFile)
writer.writerow(['Ward', 'Electorate', 'Turnout'])
writer.writerows(data)
I won’t go through it in detail here because you can see it working on Google Colab.
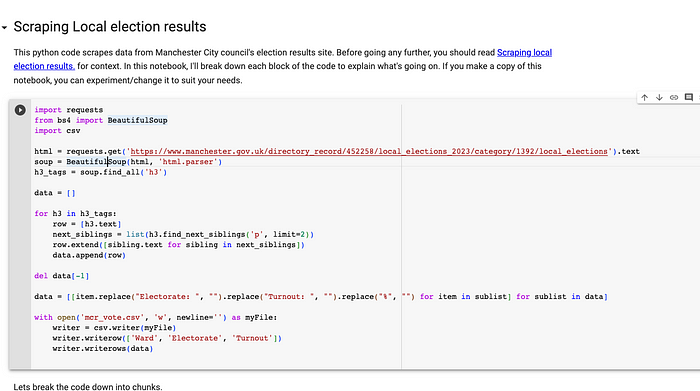
The notebook format makes it easier to see how it all works. But if you look through the code above, hopefully, you get the general gist of it. Maybe you can also see some of that XPath language creeping in.
Conclusions
I like the instant accessibility of Google Sheets for this kind of thing. But it gets overwhelmed quite quickly, especially if there are lots of elements to pick up. The code approach is much more flexible. But of course, there’s the added overhead of getting your head around the code.
It’s worth noting that on that point, perhaps now is a good time to get your head around what chatGPT and others can do when it comes to code. I wouldn’t trust it to write code from scratch. But it certainly helps in building blocks of code up as you work through a problem.
Anyway, hopefully, that was a helpful opportunity to explore web scraping, code and local council websites.
* This has always been a big thing for me working in universities where the platforms and access are variable and working with journalists where access to resources can be even more of an issue